학습 목표
1. 데이터 분석을 위한 Python 기초 문법에 익숙해질 수 있다
2. Pandas의 사용법을 익힌다
3. 데이터 분석 시각화에 필요한 matplotlib의 사용법을 익힌다
< 데이터 분석에 꼭 필요한 파이썬 문법 >
1) 변수
= 데이터를 담는 컨테이너
특정한 이름이 있는 상자에 원하는 데이터를 담아 두었다가
그 이름만 부르면 데이터를 쉽게 호출할 수 있다.
변수 선언하기
x = 5 , y = 3 , z = "Hello"
변수 호출하기
Print (x) #5
print (y) #3
2) 리스트
= 순서가 있는 데이터들의 모음집
리스트가 없으면 변수를 하나하나 저장해야하지만,
리스트가 있으면 번거로움 없이 쉽게 데이터를 호출할 수 있다.
리스트 선언하기 :
리스트는 "대괄호"를 사용하여 작성한다.
리스트 = [ 데이터 , 데이터 , 데이터, ... ]
Ex)
a_list = [1,2,3,4,5]
or
b_list - [1,2, ' hello ' , ' world ' ]
리스트 데이터 호출하기 :
리스트 데이터는 순서 (인덱스)를 활용해 출력할 수 있다.
Ex)
b_list [1] #2를 출력
b_list [2] #hey를 출력
여기서 인덱스란 리스트 안의 데이터들의 순서를 뜻한다.
※ 리스트 순서는 0부터 시작한다
3) 딕셔너리
= '사전'과 같이 "이름"과 "이름에 해당하는 값"이 쌍으로 이뤄진 데이터들의 모음집
" 원하는 정보 = 키 " 만 불러준다면
해당 정보를 쉽게 찾을 수 있어서 용이하다.
딕셔너리 선언하기:
딕셔너리는 "중괄호"를 사용하여 작성한다.
딕셔너리 = { 키: 밸류, 키: 밸류, 키: 밸류 ... )
Ex)
Student_age = { ' Jack ' : 32 , ' Ritika ' : 31, ' mark ' : 22, ' Mathew ' : 27 }
딕셔너리 값 호출하기:
값은 해당 키를 불러 줌으로써 출력 가능
딕셔너리 [ 키 ]
Ex) Student_age [ Ritika ] # 32
이제 배운 것을 바탕으로 타이타닉 데이터 분석에 활용해보자
Pandas는 데이터 분석의 데이터 분석 기본 세팅 하기 → 데이터 분석하기 과정에서 사용한다.
Pandas의 진행은 이렇다.
1) Pandas 사용 선언 하기
2) 데이터 가져오기
3) 데이터 확인 및 표 읽기
4) 공백란 제거하기
1) 데이터 분석 기본 세팅
(1) Pandas 라이브러리 사용 선언하기
= 나 지금 Pandas 사용할거야 !
(2) 데이터를 Colab으로 가져오기
= ' train.csv' 데이터 읽어와
titanic 이라는 변수에
rain.csv라는 파일을 pd = pandas가 데이터를 읽어온다!
엑셀 파일도 똑같이 읽어올 수 있다
titanic = pd.read_excel('파일이름.xlsx',engine='openpyxl')
(3) 표 읽기 및 데이터 확인
= 표 갖고 와
데이터의 처음 (n) 줄의 데이터를 출력
괄호 안에 아무런 입력이 없을 경우 5줄을 기본으로 출력
titanic.head (100) 이면 100가지 데이터를 불러와준다 !!
(4) 공백란 제거하기 (데이터 클렌징!)
null = 공백, 비어있다.
titanic 파일 중에 비어있는 게 몇 개냐는 뜻이다.
PassengerId 0 Pclass 0 Sex 0 Age 177 SibSp 0 Parch 0 Fare 0 Survived 0 dtype: int64
Titanic 중에 비어있는 것들이 나이 (Age) 에 177개나 나왔다는 결과값을 확인 할 수 있다.
공백란이 몇 개 있는지 확인을 했으니,
이제 제거해보자.
titanic = titanic.dropna() 로 제거가 가능하다.
제거하고 print(titanic.isnull().sum()) 를 한번 더 입력해서 결과 값을 확인해보니
PassengerId 0 Pclass 0 Sex 0 Age 0 SibSp 0 Parch 0 Fare 0 Survived 0 dtype: int64
Age 공백란이 지워진 것을 확인할 수 있었다.
2) 데이터 분석
(1) 상관 계수 구하기
corr=titanic.corr(method='pearson') 를 활용해서 상관관계 계수를 구한다
상관 관계를 분석하는 여러가지 방법론 중에
" ' pearson ' 방법론을 사용해서 Corr이라는 것에 그 결과를 저장하겠다 " 라는 뜻이다.
결과 값은 corr을 입력해 확인하면 된다.
현재까지 진행된 코드는
이렇고, 결과값은
PassengerId 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Survived 0
dtype: int64
| 1.000000 | -0.035349 | -0.024575 | 0.036847 | -0.082398 | -0.011617 | 0.009592 | 0.029340 |
| -0.035349 | 1.000000 | -0.155460 | -0.369226 | 0.067247 | 0.025683 | -0.554182 | -0.359653 |
| -0.024575 | -0.155460 | 1.000000 | -0.093254 | 0.103950 | 0.246972 | 0.184994 | 0.538826 |
| 0.036847 | -0.369226 | -0.093254 | 1.000000 | -0.308247 | -0.189119 | 0.096067 | -0.077221 |
| -0.082398 | 0.067247 | 0.103950 | -0.308247 | 1.000000 | 0.383820 | 0.138329 | -0.017358 |
| -0.011617 | 0.025683 | 0.246972 | -0.189119 | 0.383820 | 1.000000 | 0.205119 | 0.093317 |
| 0.009592 | -0.554182 | 0.184994 | 0.096067 | 0.138329 | 0.205119 | 1.000000 | 0.268189 |
| 0.029340 | -0.359653 | 0.538826 | -0.077221 | -0.017358 | 0.093317 | 0.268189 | 1.000000 |
이렇게 확인할 수 있다.
1주차에 배웠던 엑셀에서의 표를 쉽게 확인할 수 있었다!
표를 보면 Survived 와의 상관관계를 구하고 싶은데,
생존률과 생존률의 상관관계를 굳이 확인할 필요는 없으니,
(자기 자신이니까 상관관계가 당연히 1이므로 )
상관계수 Survived 요소가 1(최대)이 아닌 수만 불러오는 코드인
corr = corr[corr.Survived !=1] 를 입력해서 지워준다.
입력하고 결과를 보면,
| 1.000000 | -0.035349 | -0.024575 | 0.036847 | -0.082398 | -0.011617 | 0.009592 | 0.029340 |
| -0.035349 | 1.000000 | -0.155460 | -0.369226 | 0.067247 | 0.025683 | -0.554182 | -0.359653 |
| -0.024575 | -0.155460 | 1.000000 | -0.093254 | 0.103950 | 0.246972 | 0.184994 | 0.538826 |
| 0.036847 | -0.369226 | -0.093254 | 1.000000 | -0.308247 | -0.189119 | 0.096067 | -0.077221 |
| -0.082398 | 0.067247 | 0.103950 | -0.308247 | 1.000000 | 0.383820 | 0.138329 | -0.017358 |
| -0.011617 | 0.025683 | 0.246972 | -0.189119 | 0.383820 | 1.000000 | 0.205119 | 0.093317 |
| 0.009592 | -0.554182 | 0.184994 | 0.096067 | 0.138329 | 0.205119 | 1.000000 | 0.268189 |
Survived가 지워진 걸 확인할 수 있다.
이제 데이터 정리를 했으니
분석한 결과를 시각화하는 작업을 해보자
matplotlib을 이용하여 시각화를 해볼건데,
진행은 Pandas의 방법과 동일하다.
1) matplotlib 사용 선언 하기
2) 그래프 그리기
3) 그래프로 사용할 부분만 남기기
4) 원하는 그래프로 변경 하기
1) Matplotilb 사용 선언 :
import matplotlib.pyplot as plt
= 나 지금부터 Matplotilb 사용하겠어 !
2) 그래프 그리기
corr.plot()
= 그래프 그려줘 !
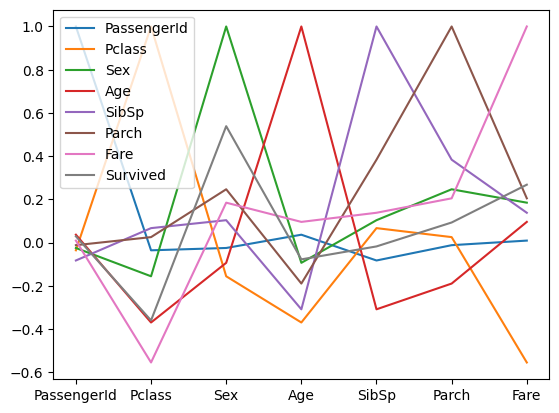
이렇게
PassengerId 부터 Survived까지 모든 데이터의 상관계수가 그래프로 그려진다.
Survived 와의 상관계수를 보고 싶으니
corr['Survived'].plot()
= corr에 Survived를 가져와줘를 입력하면 Survived 만 입력된 그래프를 가져와준다.
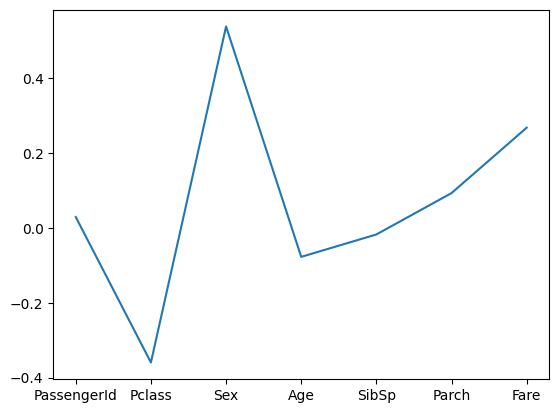
passengerid 부분은 데이터 분석에 필요가 없으므로 제거해준다
corr = corr.drop(['PassengerId'], axis ='rows')
corr['Survived'].plot()
= corr 에 Passengerid를 빼고 Survived만 찍겠다
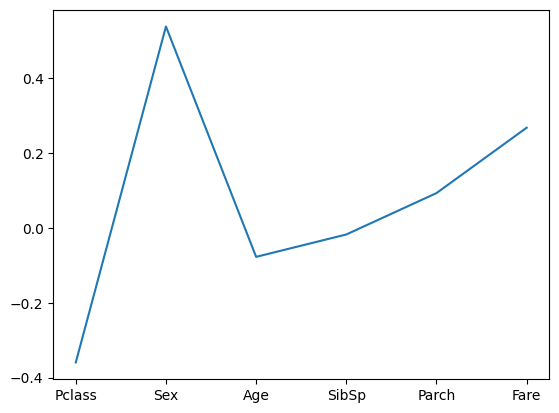
Passengerid가 없어진 것을 확인할 수 있다.
이제 보기 쉽게 막대 그래프로 바꿀거다
corr['Survived'].plot.bar()
= corr에 Survived를 막대 그래프로 입력해줘
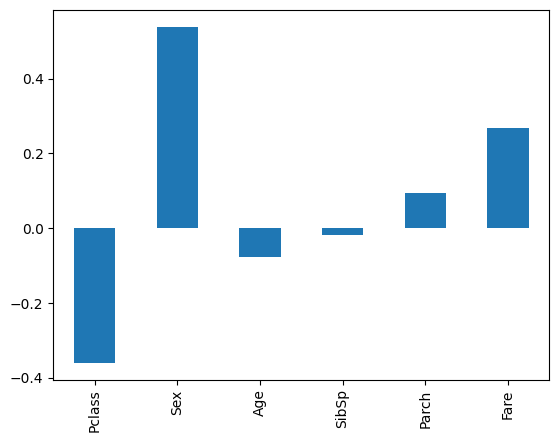
성별, 좌석 , 요금이 생존률과 가장 상관관계가 있다.
[과제] 피마 인디언 당뇨병 데이터 세트를 이용해
당뇨병 발생에 가장 많이 영향을 미치는 요소를 찾기. 단, 파이썬으로 진행
아래는 코드!
위에서 설명한 것을 그대로 응용하면 된다.
Pregnancies 0
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64
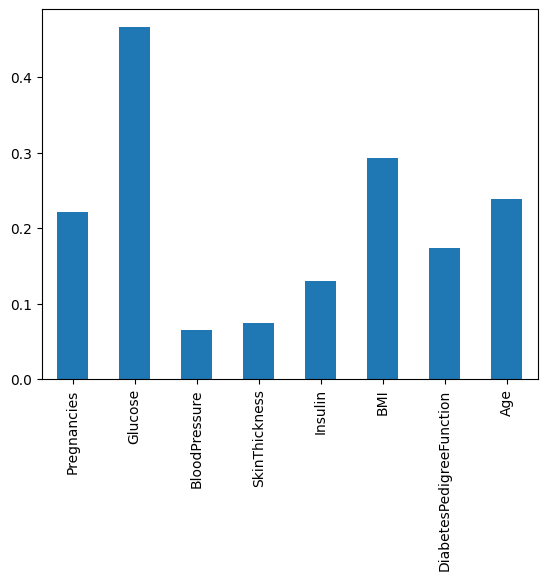
포도당 ( Glucose )가 상관관계가 높은 걸 알 수 있다
아까 배운 거 응용해서 과제를 풀어봤는데, Matplolib 적용하고 마지막으로
corr['outcome'].plot.bar(
을 입력했는데, 에러가 떠서 당황했다. 알고보니
처음에 대문자 O가 아니라 소문자 o로 적었었다..
corr['Outcome'].plot.bar(
다시 적으니 잘 나왔다!!
처음 들었을 때는 이해가 안 되는 부분이 너무 많았는데,
다시 처음부터 들으니 이해가 돼서 다행이다.
SQL 이랑 번갈아서 듣는데 헷갈릴까 걱정되지만 ~ 잘 해낼거다!
'개발 일지 > 실전 데이터 분석' 카테고리의 다른 글
| [개발 일지] 실전 데이터 분석_ 1주차 (0) | 2023.05.16 |
|---|
